Generative AI x Knowledge Graphs
Data wrangling tasks include data acquisition, data ingestion, data extraction, data cleaning, data transformation, exploratory data analysis, and data pipelining for ML tasks. Data variety, dimensionality, complexity, duplication, provenance can further complicate this data wrangling process.
A big part of implementing data science and machine learning/AI in organizations is data wrangling. Data wrangling accounts for between 70-80% of data science. Data wrangling can mean many things. In general, data wrangling tasks include data acquisition, data ingestion, data extraction, data cleaning, data transformation, exploratory data analysis, and data pipelining for ML tasks. Data variety, dimensionality, complexity, duplication, provenance can further complicate this data wrangling process.
Generative AI is transforming software engineering. I have high hopes that it will also make data wrangling a bit easier for data architects, data modelers, data analysts, data engineers, and data scientists.
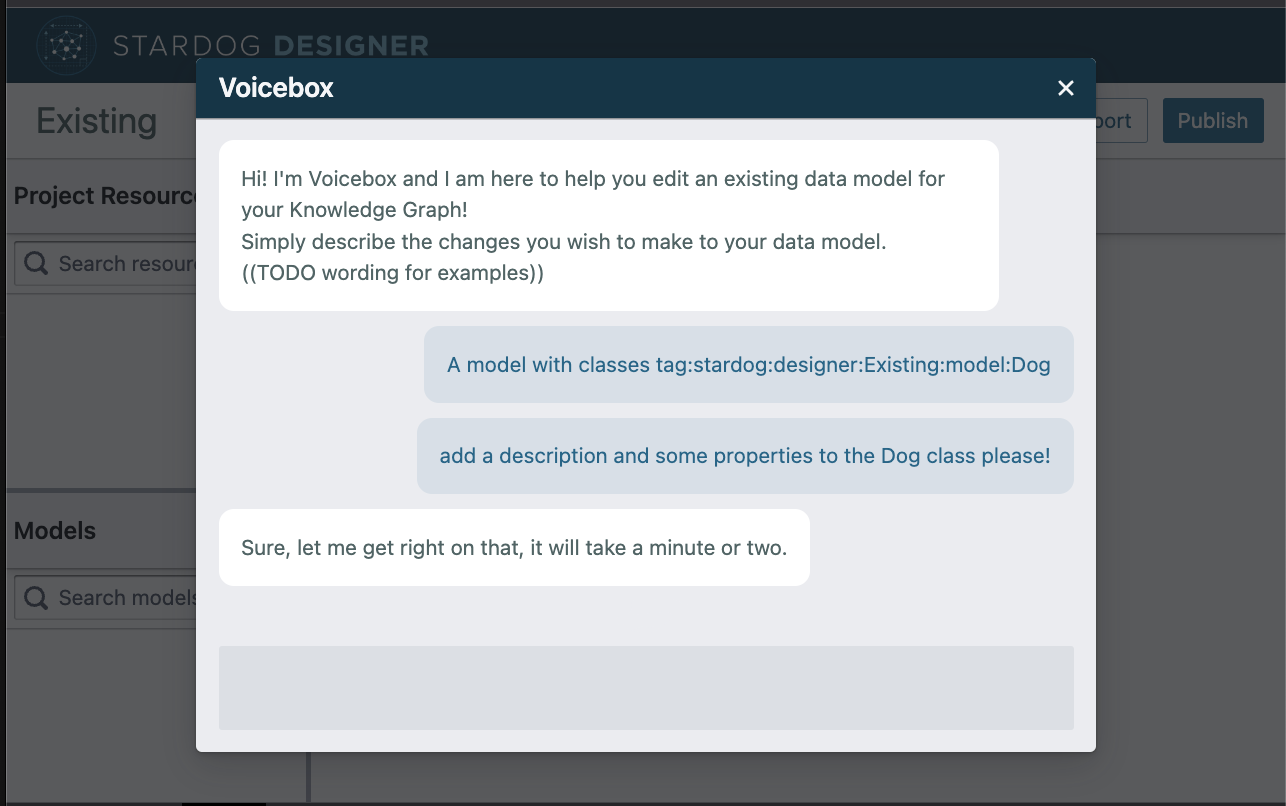
Silectis is leveraging this for data engineering. Another company, Stardog, is trying to do exactly this by bringing the power of generative AI into knowledge graphs. Stardog trained their own large language models for Stardog Voicebox. Voicebox is a smart assistant that helps upstream data professionals build data models (a key way to understand relationships among data at scale) for knowledge graphs. All this is done with simple prompts. I can see generative AI doing a lot more the area of knowledge graphs for data science and business professionals alike.
This is a game changer.
 Mike Grove
Mike Grove